
从实习至现在,我做Java爬虫相关业务已将近3年。因近期公司的产品经理希望我可以向同事分享自己的爬虫经验。因此就分享前,在此整理自己的爬虫经验。
什么是爬虫
爬虫并不是某一种计算机语言下的特定技术,而是一项通过计算机程序,模拟浏览器请求,模仿用户访问网站进行的数据采集的解决方案。
平常大家说到爬虫,总会提到Python或者Java。这并不是因为只有Python和Java能做爬虫,而仅仅是因为这两种计算机语言在社区中已有成熟易用的包且用户群体大。
因本文作者专修Java,故若文章后续存在Demo,均会是Java。
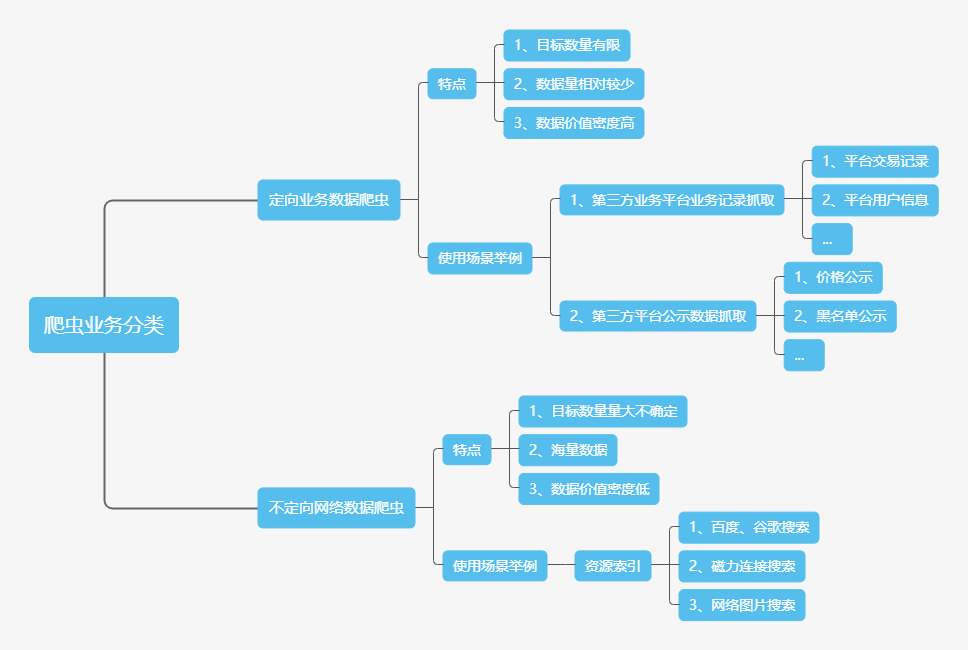
从使用用途来说我们可以将爬虫分为以下两类:
- 定向业务数据爬虫
- 不定向网络数据爬虫
两种分类下的爬虫的特点和使用举例如下图所示:
因为不定向网络数据爬虫这一方向较大,且我并没实际接触过对应开发。下文的一切将会围绕定向业务数据爬虫进行讲解说明。
定向业务爬虫
定向业务爬虫(下文简称定向爬虫)是我们做Web应用开发最常遇到。在定向爬虫开发中,我们一般需要进行:
- 验证
- 目标数据获取
- 初步解析以及存储
这三部分的开发,而我将会以:
- 请求与解析
- 验证
- 部署、成本与总结
这三个方面对这三个部分的开发经验进行分析总结。