
前面说到爬虫本质就是用程序模拟浏览器访问网站来获取数据,那这一节我们就来说一下怎样去请求并解析成我们需要的数据。
Http协议
在爬虫中,我们遇到的传输协议基本上就只会有Http协议。既然我们要伪造浏览器客户端请求服务器获取数据,那么我们就需要先了解我们需要伪造的目标http协议的构成。
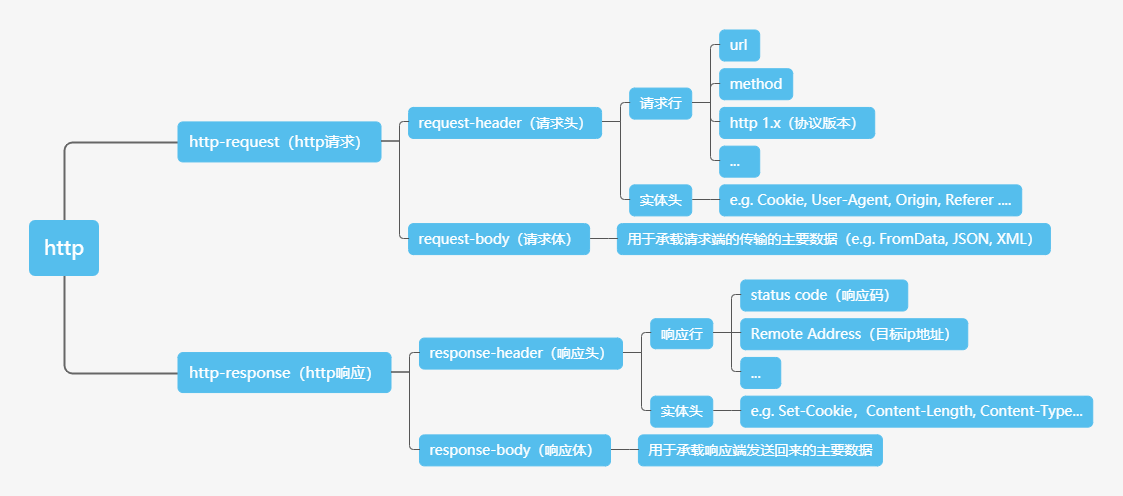
在平常的开发中,相信我们都接触过后台对接第三方应用接口的情况。因此这里我们不对如何发起Http请求进行阐述。我们只说明与平常请求第三方应用接口,爬虫需要的请求与一般第三方应用接口需要有什么不同。
对于一些“卖”数据的网站而言,数据是网站的资金来源。他们绝对不会让开发者轻轻松松去请求他们的接口将数据全拿走。因此他们会对请求设定一些限制,从而鉴别服务器发起的请求和普通用户从浏览器发起的请求。而他们往往都是通过鉴别上图中请求头中的实体头来进行区分的。因而我们只需要伪造好实体头即可跳过网站的这些请求限制。
通常我们需要伪造的请求头有如下这些:
User-Agent
User-Agent是浏览器自动生成的,用于标识用户的客户端类型与版本,这是最常用的一个请求头。Referer
Referer是浏览器自动生成的,用于标识该请求在访问到哪个页面发起的。这个标识通过用于做防盗链,防止第三方网站直接引用该网站的资源。同时,它也可以作为请求的队列的顺序标识来鉴别请求真伪Cookie
这个应该不用多说,就是通常用于进行网站用户登录标识鉴别(登录验证相关的内容会放在下一部分进行介绍)
在伪造客户端请求时,除了以上这些请求头,我们还要注意一些网站自定的一些请求头。比如说,JWT的x-token等。
如何找到我们需要的请求
我们要伪造请求,那么我们要先知道我们需要的请求是哪个。下面就来说一下常用的三个方法。
方法一、利用浏览器Network监听
浏览器按F12,打开浏览器的开发者工具。其中有一个Network的标签页。这一个是浏览器自带的,用于监听当前页面的请求监听器。
下面以找出百度搜索的请求为例,我们先在百度的搜索框输入我们要搜索的内容。然后按F12打开Network清空监听内容准备监听。
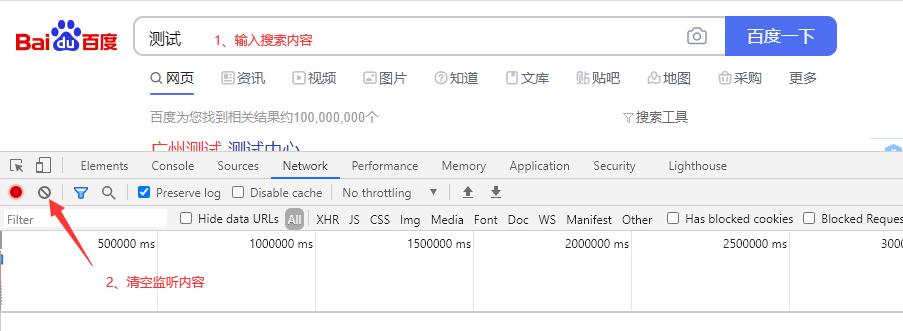
点击请求接口的触发器,在这个示例里,触发我们需要去找的百度搜索请求的触发器就是百度一下按钮,在点击百度一下后,浏览器就会发起搜索请求。列表中就会列出相关的请求信息。因为百度搜索是异步搜索,不是利用html的form表单进行提交跳转的搜索。因此我们可以点击XHR进行筛选。
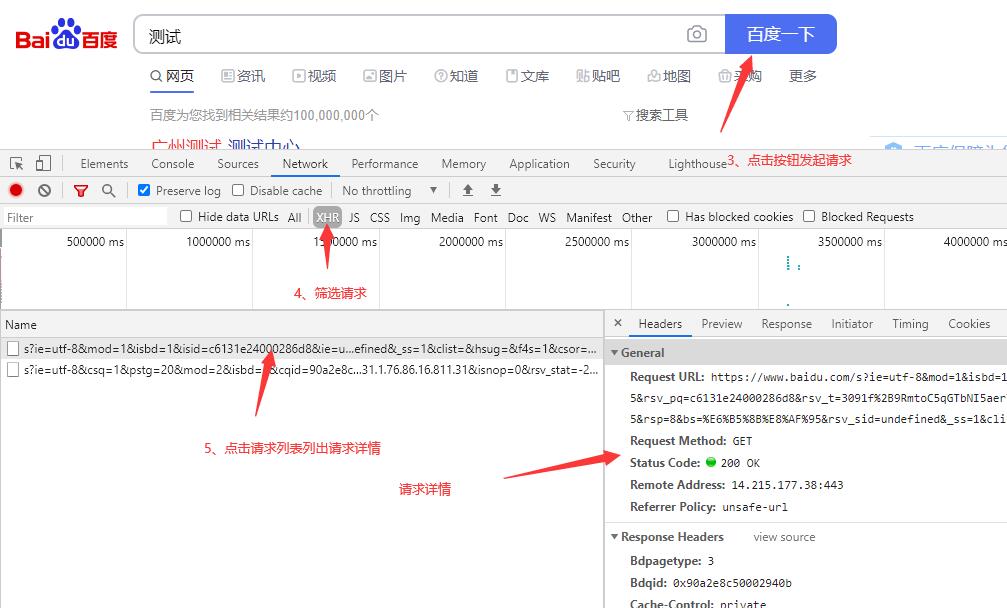
XHR指的是浏览器的内置对象XMLHttpRequest发起的请求
通过查看请求详情中的请求参数,对比我们的输入的搜索内容,即可找到我们需要找的搜索接口。
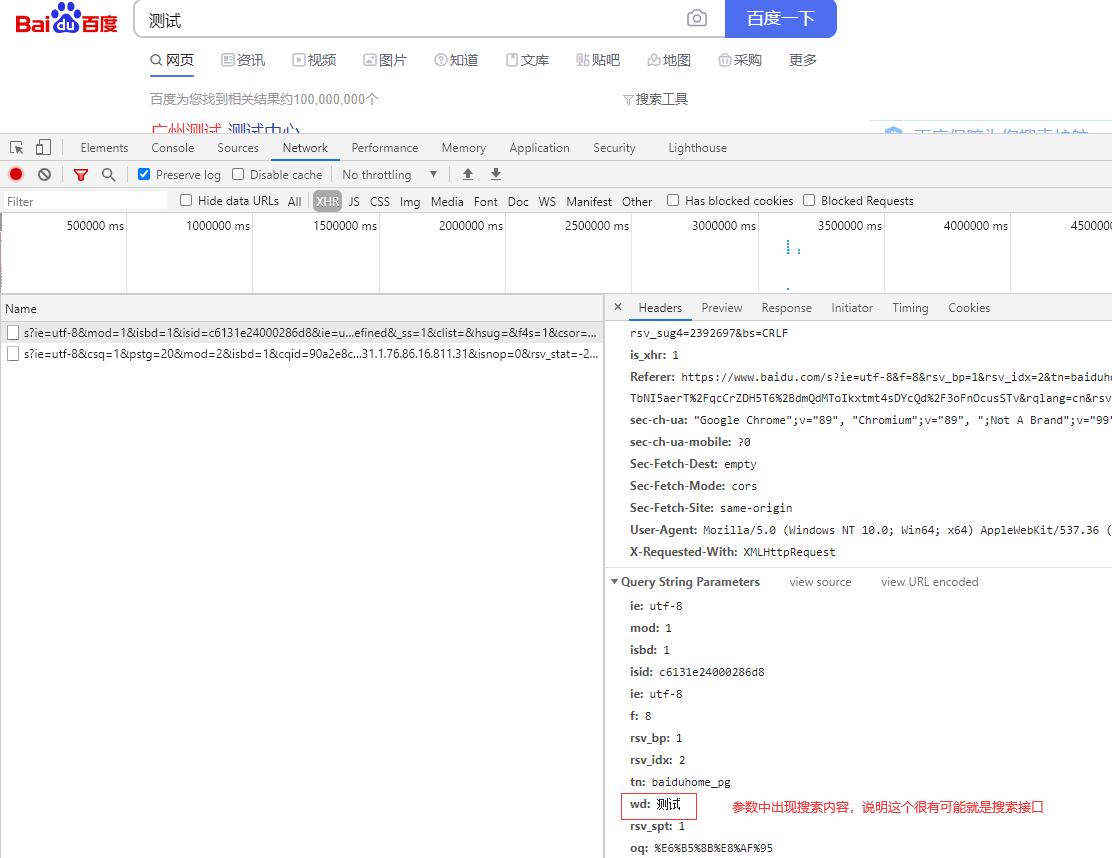
Network是十分方便简单的一个获取请求的手段,但这个方法也有一个比较致命的缺陷。那就是针对一些会诱发页面刷新的请求或者交互时,它会清空所有请求记录。这导致它无法捕捉到会刷新当前页面的form表单之类的请求。
方法二、阅读网页源码
对于网站的架构一般可以按页面渲染方式分为以下几类:
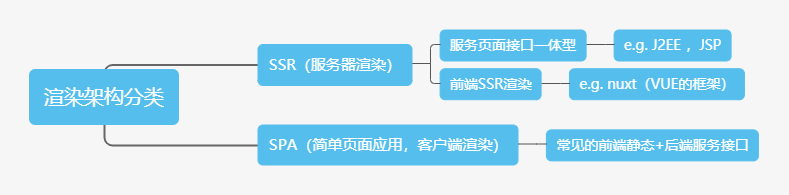
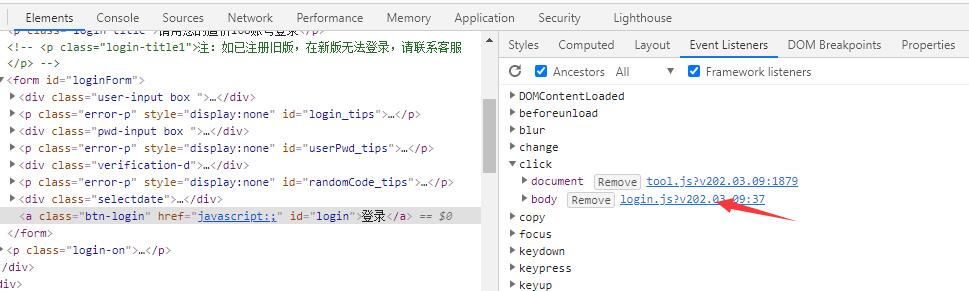
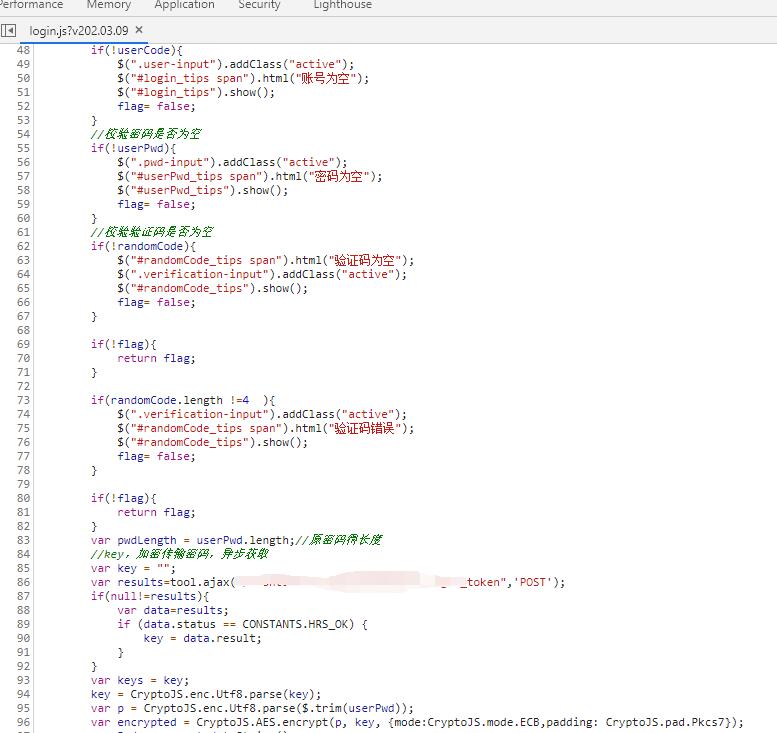
在上图中服务页面接口一体型这一类中,在开发中往往会将JavaScript脚本直接在页面上编写或直接进行外部静态引用。这些脚本通常是没有进行过打包处理(去空格换行+代码混淆),因此可直接阅读。我们只需通过事件触发点(事件按钮),找到对应的JS函数,即可通过阅读JS代码知道其对应的接口以及请求参数与封装方式。
方法三、Wireshark本地流量包抓取分析
Wireshark(前称Ethereal)是一个网络封包分析软件。我们可以利用它,对本地机器的访问包进行抓取解包分析。
如何使用wireshak
这里我们说下其简单使用,如果读者曾在网络安全课上学过,可选择直接跳过。
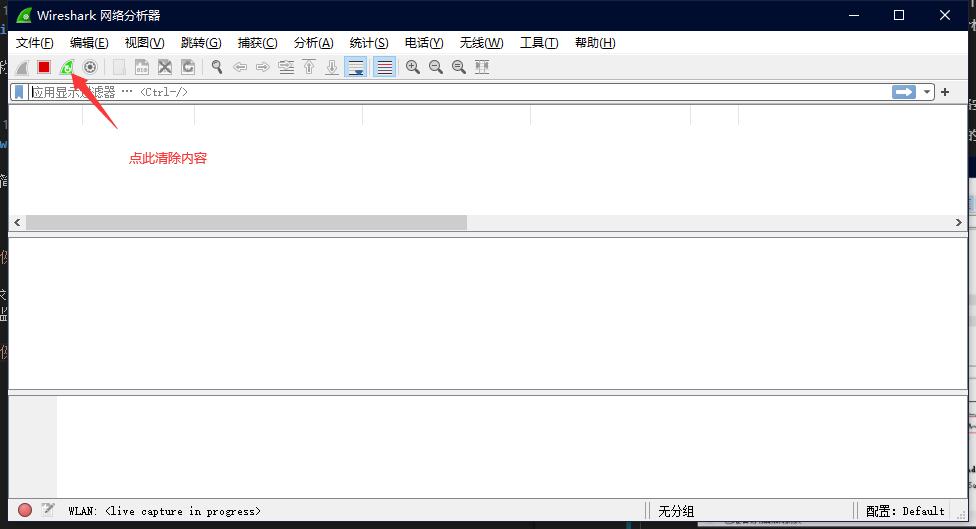
1、打开软件后,点击双击当前用于访问网络的网络接口进行监听
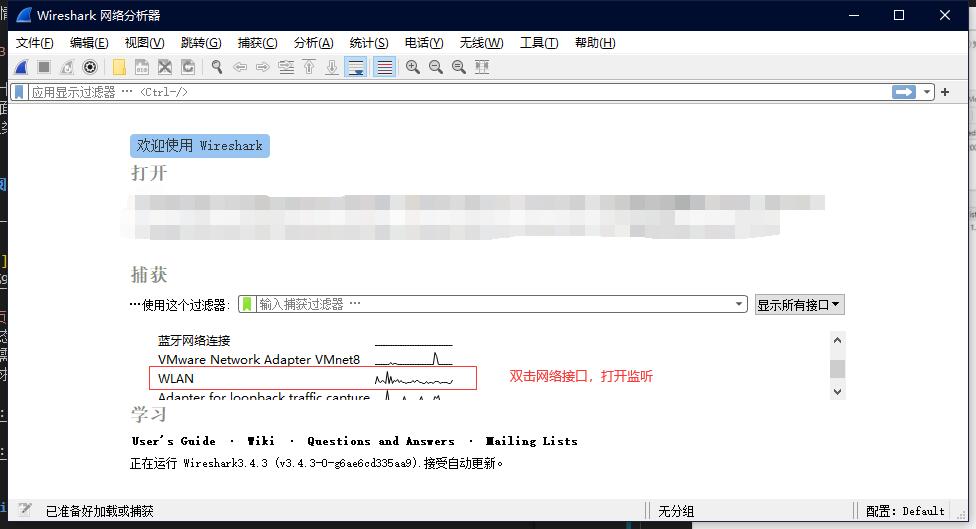
2、打开触发请求前的网站页面,将其运行到待触发请求状态。待页面所有请求加载结束后,清空wireshark请求监听记录来准备监听目标请求。
3、触发浏览器请求,输入筛选条件筛选抓包记录。在抓包记录中,找到我们需要的请求。
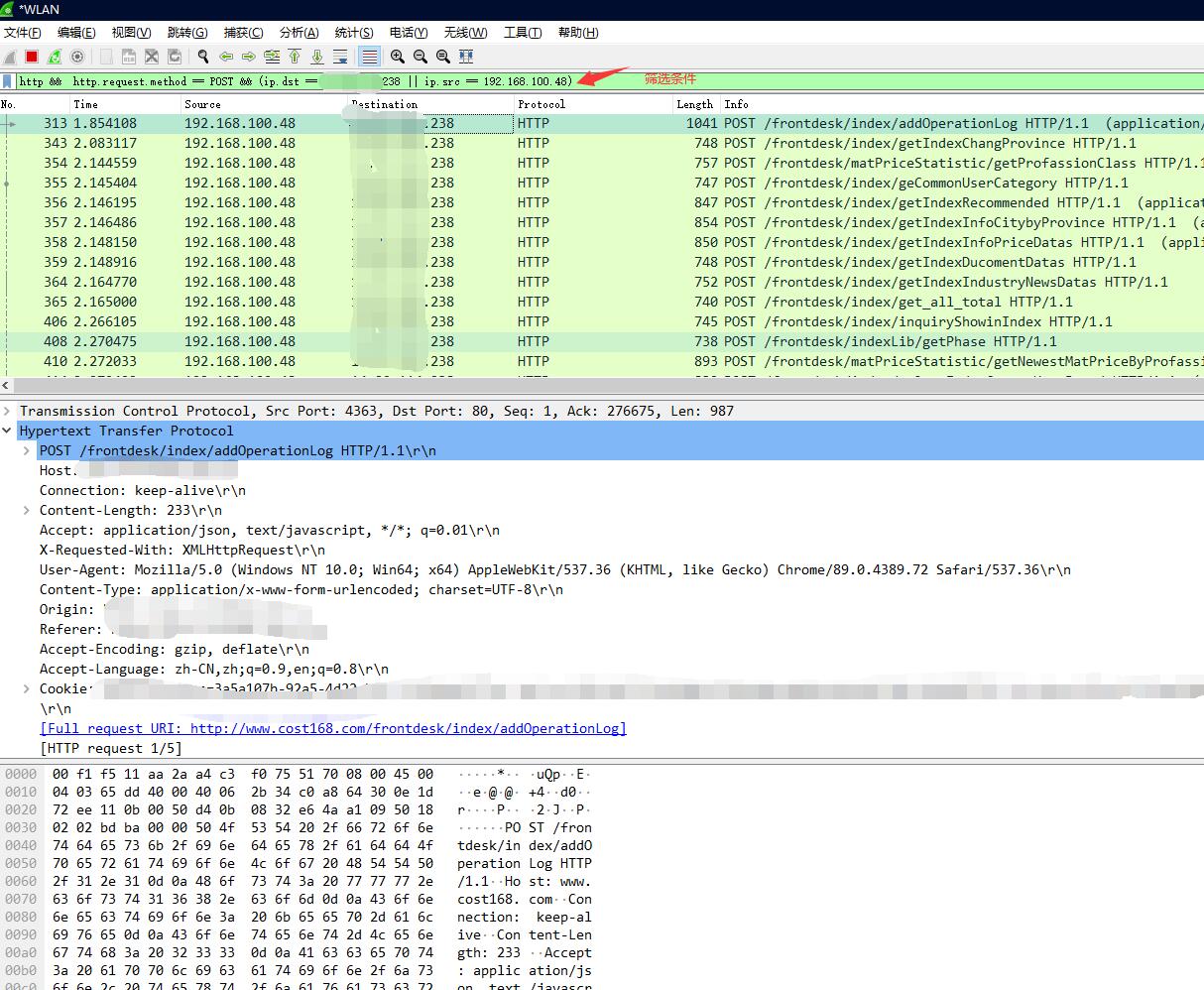
常用的筛选表达式有
http,udp,tcp,tls等协议名称筛选http.request.uri请求资源路径筛选http.request.method请求方法筛选ip.src请求发起地址ip.dst请求目标地址
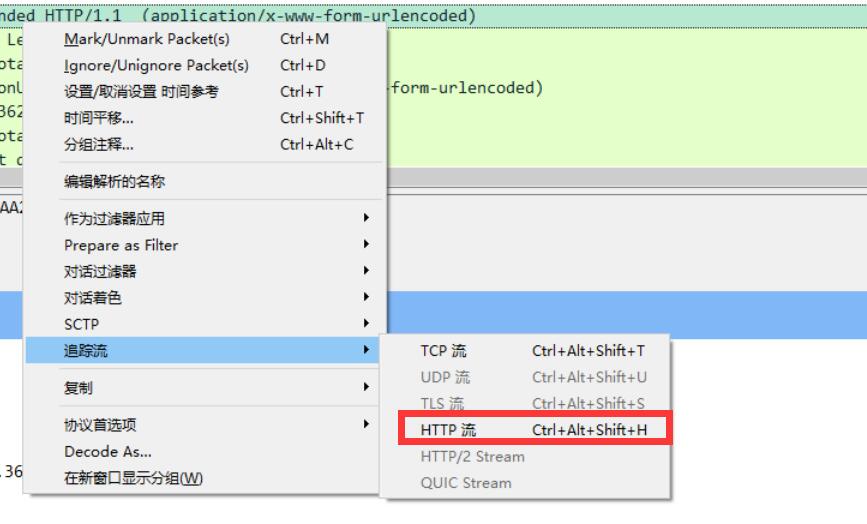
4、右击请求记录,点击跟踪流-http流,即可找到其请求对应的响应信息
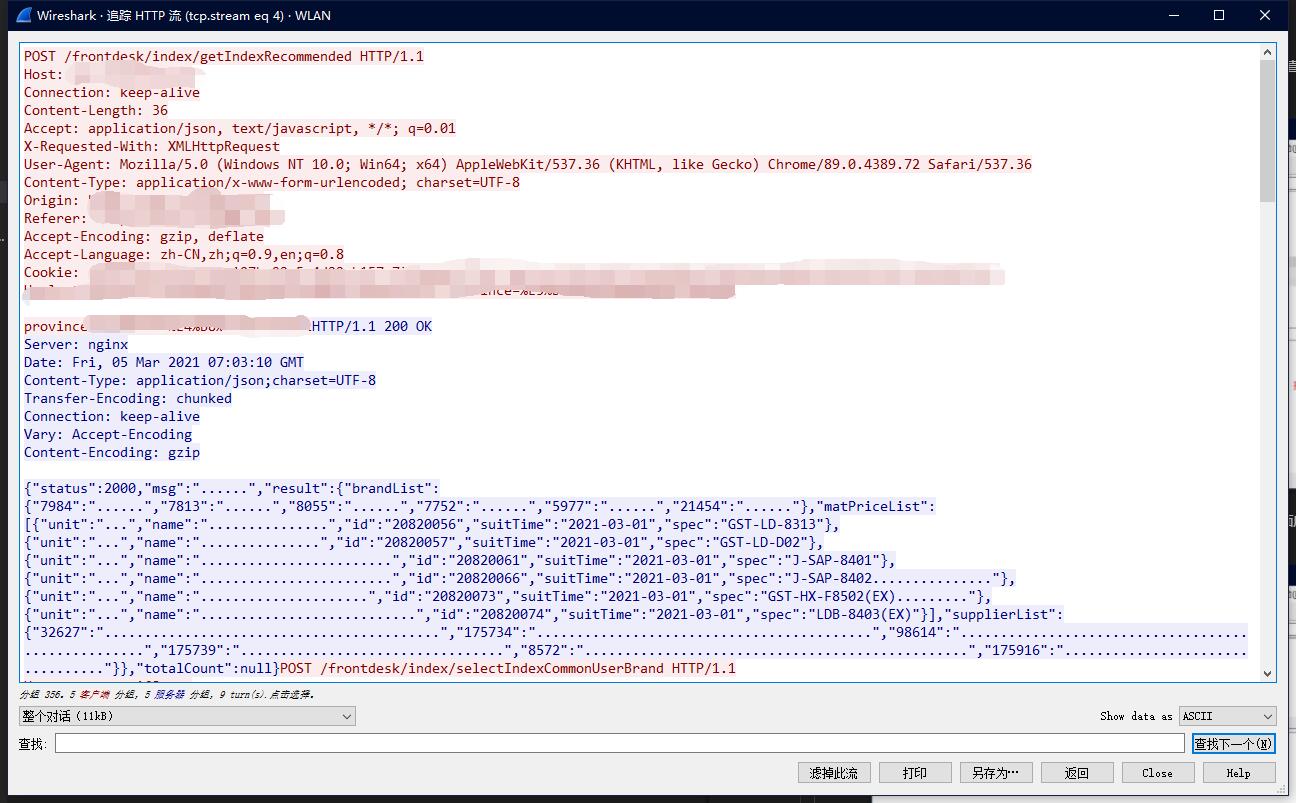
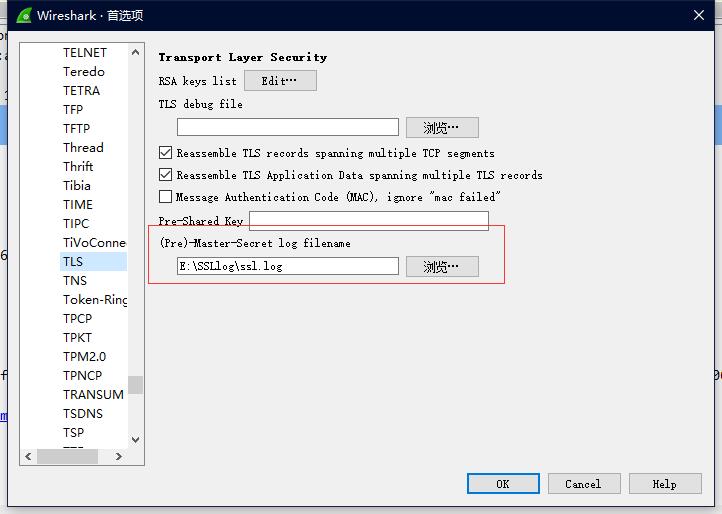
注意:当需要请求的目标使用的是https协议时,我们需要对其进行解密。https与http协议不同,https通过TLS协议(SSL协议是TLS协议的前身)进行了加密。我们需要将请求内容进行解密才可以看到明文。点击解密教程查看解密教程,要注意的是,在文中的解密教程说到的配置SSL日志的首选项目录是
Protocols-SSL是旧版的配置目录。在当前版本(目前我用的是3.4.3),这个版本没有SSL协议选项,只有TLS选项。因此我们设置这个目录时需要更改为Protocols-TLS下设置。
解析请求回来的数据
通常我们爬虫需要请求回来的都是以下这些类型的数据:
- JSON
- HTML
- XML
- 图片,视频等文件流
JSON和文件下载处理相信大家都很熟悉,所以这里我们只说说HTML和XML。
HTML是XML的一种,只是其有固定的xtd信息标准。HTML和XML都是树状标记语言,其处理方法都是相似的。在Java中,其对应的优秀解析包如下:
HTML解析包Jsoup
1 | |
HTML解析包Jsoup
1 | |
首先,当我们拿到一串完整的HTML代码串串时,我们首先要将其解析为一个文档对象(Document)
1 | |
假如需要查询target的子节点,可以将Element视为Document以上面的方式继续往下查。现在我们解析到节点后,进行数据提取。
1 | |
XPath
XPath是XML中的绝对路径表达方式。在请求结果固定,能保持一致时,可以考虑使用XPath来进行数据定位。HtmlUnit中就提供了XPath进行节点定位。但由于爬虫中很难说有每个请求回来的XML或HTML的绝对路径是一致的情况,而且浏览器中存在JS对请求回来的Html进行渲染修改的情况,因此XPath在爬虫中并不实用。但由于存在这个定位方式,所以姑且还是提一下。
扩展阅读:XPath语法
小结
这一节总结了爬虫中分析请求与解析数据这两部分的个人经验。但认真有看朋友应该有发现,在聊到请求时,都是没有说到验证的情况。这里没有聊到验证这块,是因为验证这块比较重要,我打算将在下一篇文章单独聊这一块。因此,如果看到这里,我还没更新下一篇文章的朋友,敬请期待。